12 Salesforce Apex Best Practices
Whether you’re a developer or an admin, if you’ve been working on the Salesforce platform for more than a few minutes, the chances are you’ve heard the term ‘best practice’ thrown around. But what exactly does it mean?
It is a term we use for a technique or approach that is widely accepted as superior to alternative approaches, so much so that it is generally considered to be the standard way of doing things (and doing otherwise will raise more than a few eyebrows!). In this blog post, we’re going to examine some best practices for Salesforce Apex, understand why they’re best practices, and ask if there can ever be a good reason to intentionally ignore them.
1. Bulkify Your Code
Bulkification of your code is the process of making your code able to handle multiple records. This is mainly true for triggers, where up to 200 records could be run through at once, e.g., from a data load. If your code hasn’t been written to take that into account, it can lead to errors being thrown, or worse, unexpected behavior.
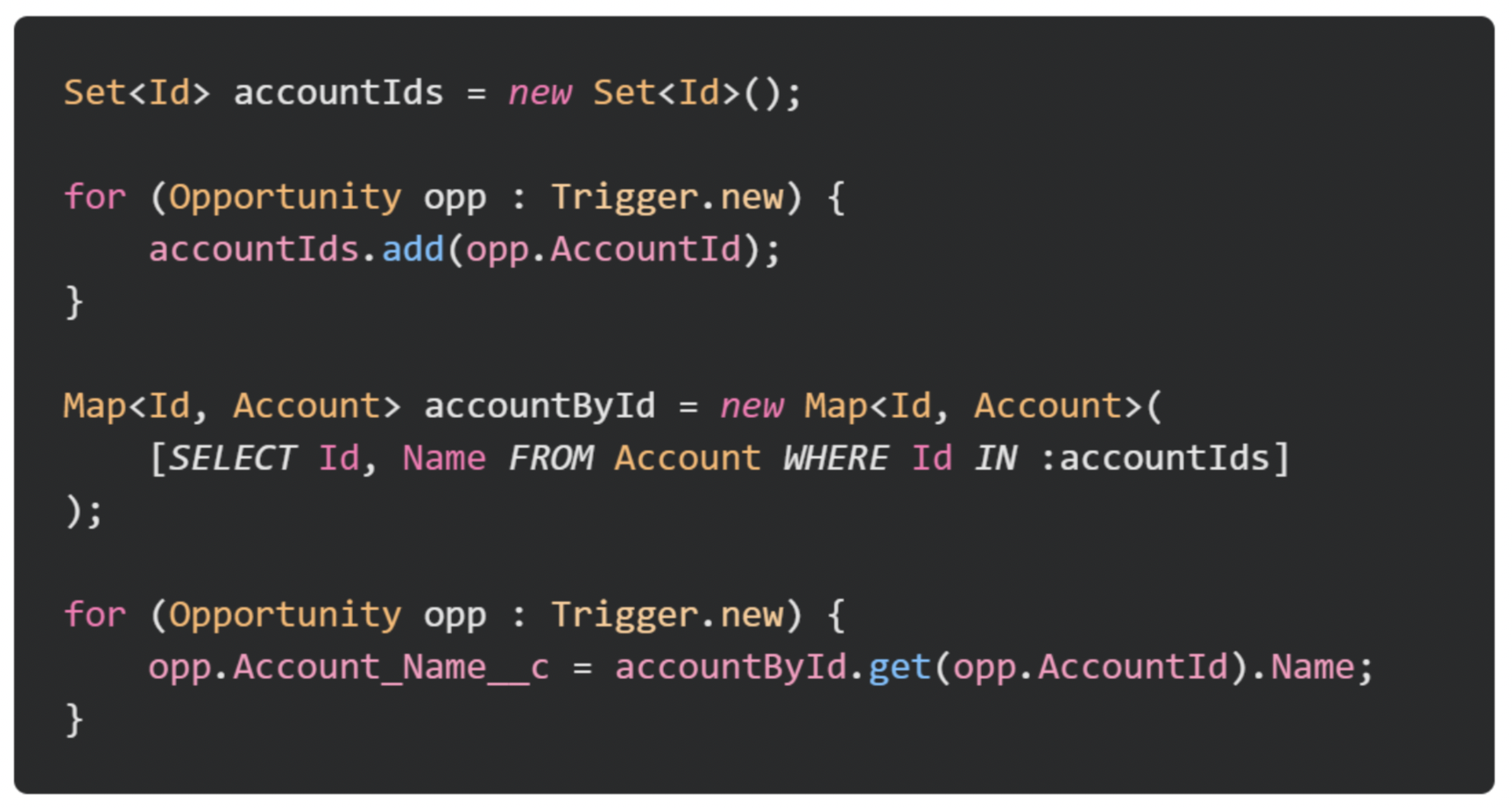
Take a look at the code below – it shows an example of code that hasn’t been written with bulkification in mind. In trigger, only the first opportunity would be processed, and any others saved in the same transaction. Depending on the business process, this could be a catastrophic bug.

Below is the same code set up to handle the full batch of records in the trigger, meaning all 200 records would be correctly processed in a single trigger invocation.

We can also bulkify our code to help improve the performance of a piece of code, where we can reduce the number of queries or other expensive operations. An example of this is using Maps to access related data more efficiently about a record during processing.
Consider use of maps can greatly reduce the complexity and the amount of time it takes your code to run by reducing the overall lines of code to be executed when compared to iterating over lists.
The only time you may choose not to bulkify your code is when you can guarantee the number of records in an invocation will be low – this may be from an API or an Apex action invoke via a screen flow. However, due to the ease of bulkifying most code, you should probably get into a good habit of doing it regardless!
2. Avoid DML/SOQL Queries in Loops
There are times when you may wish to insert/update multiple records at once, or query sets of records based on specific contexts. You may be tempted to either query or run the DML on these records while within your for loop, because what’s the worst that can happen? Well, quite a lot…
SOQL and DML are some of the most expensive operations we can perform within Salesforce Apex, and both have strict governor limits associated with them. So, sticking them into a loop is a recipe for disaster, as we can quickly and unknowingly reach these limits, especially when triggers are involved!
For DML statements, we can shift those statements outside of the loop and instead, within our loop, we can add the records we wish to perform those operations on into a list and perform the DML statement on our list instead. For almost all situations, this is the safest and best approach.

Migrating SOQL to be outside of a loop can be a little trickier, as it really depends on your context. Let’s take the example of calculating the number of contacts against an account when a new contact is inserted. In this scenario we would want to iterate over all our contacts, get the Account Id for each, and place it into a set. We can then perform a single query outside our set using “AccountId IN :accountIds” and place the results into a map. Finally, we can simply iterate over the contacts once more and get the Account from our map.
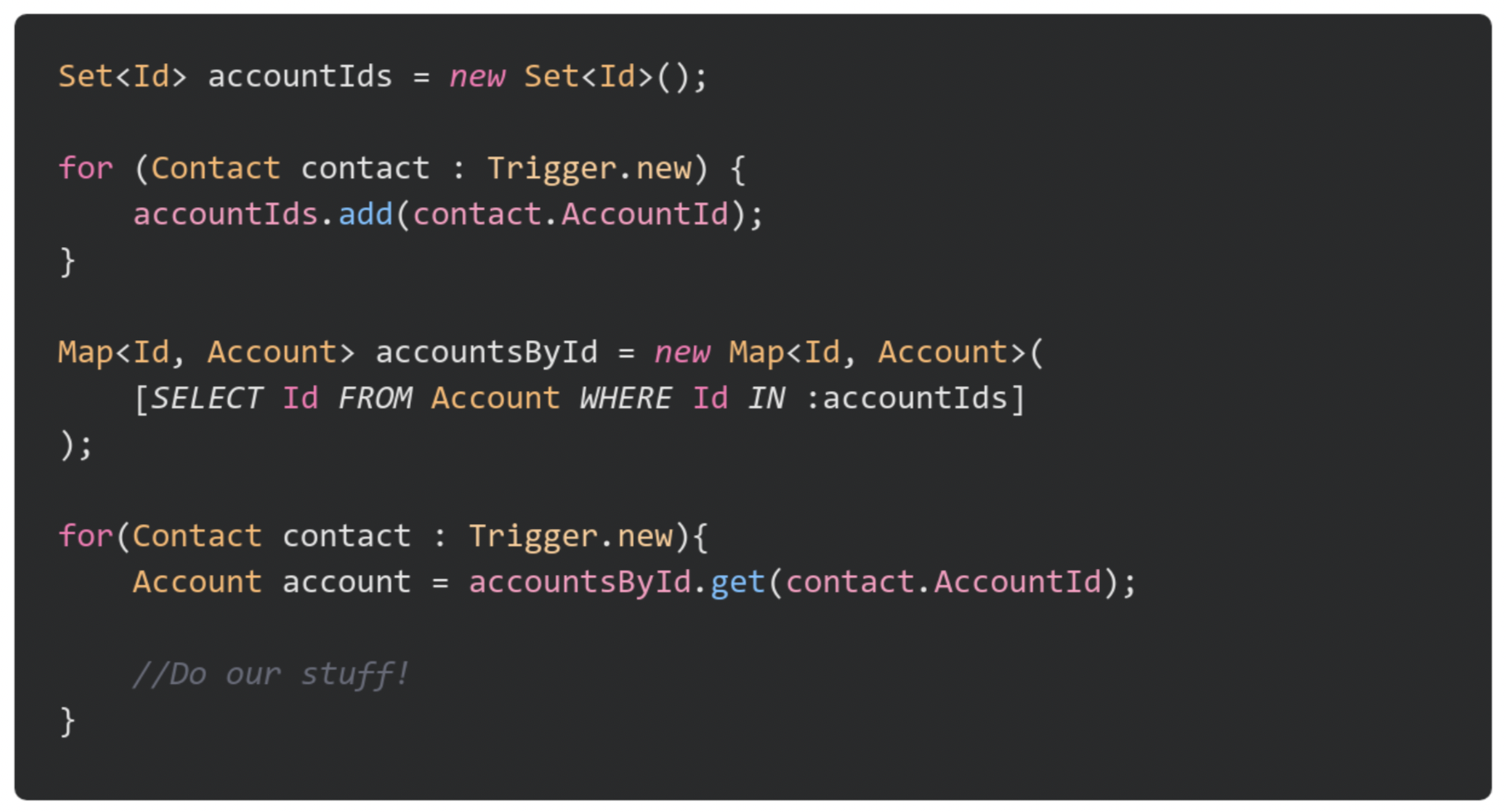
Both of the above techniques not only improve our performance and help safeguard against governor limits, but also help improve the readability and maintainability of our code by allowing us to more easily modify it and add new functionality (if required).
3. Avoid Hard-coded IDs
Consider the scenario: you need to always set the Account lookup on a specific record type of Contact to be a specific account. You may consider hard coding this variable, but that would be a bad idea!
Hardcoding IDs might work fine and without incident when they are developed, but as soon as we migrate our code into production, those IDs will no longer reference the correct record. This is especially true for Record Types created in a sandbox and then migrated into production. Consider the opposite situation: if we create a sandbox from production, our hard-coded IDs will no longer point to the correct records.
If we wish to utilize record types, instead we can reference them via their DeveloperName which will be consistent across environments.
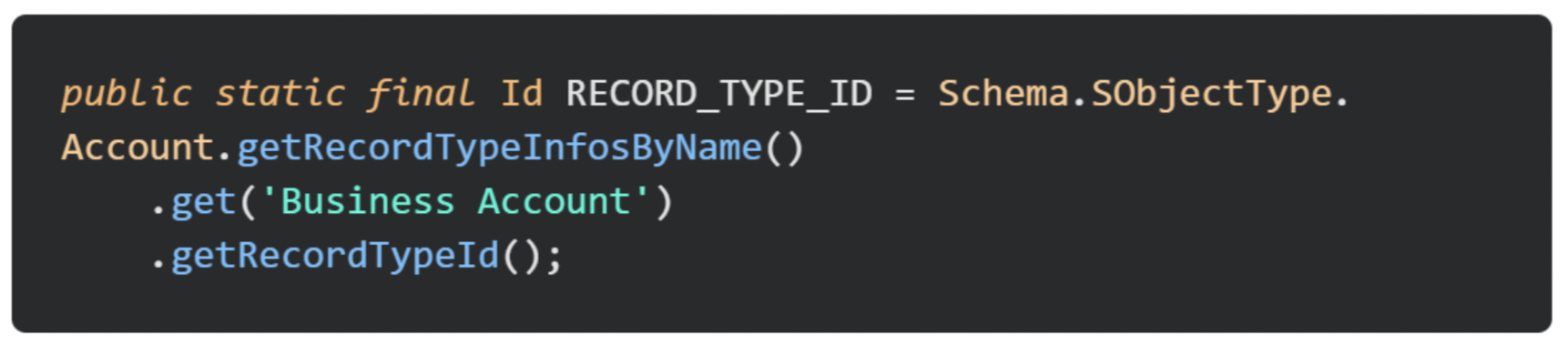
If the ID we wish to use relates to a specific record, we can instead store this ID into custom metadata and retrieve the value at runtime, allowing us to freely change the value between environments, or as requirements change.
There is only one scenario where we don’t need to follow one of the two above approaches, and that is where we are explicitly referencing the Master Record Type. This is the special default record type and is fixed across all instances. However, just because it is static now doesn’t mean it always will be, and so we should probably also store it in custom metadata (if required), just to be on the safe side.
4. Explicitly Declare Sharing Model
When we begin writing a brand-new class, one of the first things we should do is declare our sharing model. If we require our code to bypass record access, we must always declare without sharing, but when we want it to enforce sharing rules, developers can often find themselves skipping this step.
Explicitly declaring our sharing model allows us to show our intent to anyone else who works on our code in the future (which could even be yourself!). This allows them to more easily understand what’s going on within the code – omitting it obfuscates our intent.
The only time you can safely omit it is when your class doesn’t perform DML or queries. However, if there’s the possibility of this happening, or if you want to play it safe, it’s wise to declare the class’s sharing model anyway, specifying it as ‘inherited’ to allow a consumer of your class to control the model instead.
5. Use a Single Trigger per SObject Type
A very easy one to remember and to implement, the practice of utilizing only a single trigger per object is one burnt into the minds of many a developer (and for good reason!). But why exactly is this rather simple ‘best practice’ such a vital one?
When multiple triggers are defined on a single object, when a record is saved and the triggers are invoked, the order in which the triggers are run cannot be guaranteed – for all intents and purposes it is random. It’s common for individual actions within a trigger to have an order of priority, or it may have a prerequisite on a previous action having been completed (e.g., assigning a parent lookup which is then expected to be populated in the next action).
Having a random trigger order also introduces randomness into our code – this randomness makes it harder for us to debug and develop code since we always have an element of randomness and can no longer accurately replicate scenarios.
6. Use SOQL for Loops
One of the many, and more esoteric, governor limits within Salesforce Apex is the heap size limit. This a runtime limit on the memory our code consumes dynamically as it runs (an oversimplification!), and if our code exceeds this limit, the governor system will terminate our transaction.
When we query a large set of records and assign the results to a variable, a large portion of our heap can be consumed. While this might be fine during test runs where the volume isn’t as large as in a production environment, as the queried dataset grows in volume, more of our heap will be consumed and the results of a query could easily push it over the limit.
Instead of assigning our query results to a variable, we can place our query directly as the iterable variable in our for loop. This causes some behind the scenes changes to how the query is performed, causing the results to be chunked and processed much more efficiently and transparently, preventing us from running into heap limits we may have previously encountered.

The only time we might want to avoid doing a SOQL for loop is if we are performing an aggregate query. These queries don’t support the underlying mechanism that enables the more efficient chunking, and instead will throw an exception if the result returns more than 2000 rows.
7. Modularize Your Code
When we are writing code for an org, the chances are that sections and pieces of that code are repeated throughout the codebase. One may be tempted to simply copy and paste these methods or code blocks into different classes, but this very swiftly creates an unmanageable mess code!
Imagine the scenario: you’ve written a useful method to help assist build dynamic SOQL queries. Another requirement comes up which you know will benefit from this method, so you copy it into your new class, and it works well! Three weeks later a rather severe bug has been found in the initial consumer of your method – which you promptly fix. But now you need to go and apply this fix to the other class you added it to. This very quickly becomes unmanageable, as you need to update every place it’s been copied to, and each time it introduces a greater risk of further bugs due to human error.
Instead, what you should be doing is placing these reusable pieces of code into their own self-contained classes, and calling these classes and methods where you require that functionality. This can massively reduce the complexity of your code (which requires these methods), and when a bug is found in your module, it only needs to be fixed once – you can be confident it will be fixed wherever that code is consumed.
Having a set of well-tested and well-written modules to draw from is a sure-fire way to accelerate your development, and it will likely increase your development experience.
Make sure you don’t fall into the trap of building monolithic utility classes (monolithic trigger handlers are a common issue!) – classes that are doing way more than they should be. These classes become very difficult to maintain, and if multiple developers are working on a project, avoiding conflicts is a nightmare! Utility classes should be small and serve a specific purpose. If you can’t wholly define a class’s purpose, it might be getting too big, and a ‘splitting’ may be in order.
8. Test Multiple Scenarios
Salesforce mandates that we have at least 75% code coverage when we wish to deploy Apex code into production, and while having a high number of lines covered by tests is a good goal to have, it doesn’t tell the whole story when it comes to testing.
Writing tests only to achieve the code coverage requirement shows one thing: your code has been run, and it doesn’t actually provide any value other than showing that in a very specific scenario (which may or may not ever happen in practice!).
When writing our tests, we should worry about code coverage less, and instead concern ourselves with covering different use cases for our code, ensuring that we’re covering the scenarios in which the code is actually being run. We do this by writing multiple test methods, some of which may be testing the same methods and not generating additional covered lines, each of which runs our code under a different scenario.
For example, this could be covering a positive test case and a negative test case in a trigger. After we’ve run our tests, we then want to validate that the code has actually performed its intended action, and if it hasn’t, manually fail the test.
Tests like these provide far more value than simply writing tests for code coverage; these types of tests can act as an early warning system for issues which may arise when an admin adds some new functionality, or a different piece of code gets changed. Testing for these scenarios ensures we are alerted about the issues and can resolve them (before hitting production and causing late nights!).
9. Avoid Nested Loops
Loops inside of loops – sometimes it can’t be avoided. You simply need to iterate over one thing related to another. Good stuff, right? While there may not seem to be anything immediately wrong here, and the code could very well run perfectly fine without running into performance issues or governor limits, the issue here is more one of maintainability and readability.

Every time we have a block of code, any time we need to add a loop – which may or may not have some complex logic within it – it increases the cognitive complexity, which is how we measure the difficulty of understanding a piece of code. Adding nested loops is a very fast way of increasing our cognitive complexity to a point where a different developer (or yourself in a week’s time!) will struggle to intuitively understand a piece of code, requiring much more effort to debug or make any changes to it.
Rather than using nested loops, a good strategy is to abstract your logic into separate methods (which perform the logic themselves). This way, when we’re looking at a block of code from a higher level, it is far easier to understand. Abstracting our code out like this also has other benefits, such as making it easier to test specific aspects of our code.

10. Have a Naming Convention
Naming Conventions tend to be a hot topic in any developer team. The benefits are clear if everyone follows them, as they make it easier for other people in your team to understand what’s going on within an org. The specifics of what makes your (or your team’s) naming convention are up to you to decide. But following this will reap plenty of benefits when it comes to maintenance and collaboration – there’ll be less head scratching while you figure it out, so you can spend more time on the fun stuff.
11. Avoid Business Logic in Triggers
This is another best practice burnt into the minds of most developers, and one which we have all probably broken at some point! This one can also be referred to as “Avoid logic in Triggers”, but regardless of how it’s referred to, the intent is the same.
When writing triggers, if we place our logic directly in the trigger, it becomes very difficult to test and maintain. Instead, what we should be doing is using our trigger to call classes specifically designed to handle our logic – these can then be easily tested, maintained, and reused. We commonly call these classes TriggerHandlers.

These TriggerHandler classes accept the inputs from the trigger and then finally call the specific classes holding the business logic that we write. They can be simple, with us updating the handlers to call our new code as we add it, or complex, utilizing things such as custom metadata types to allow admin configurability to our triggers.
A common trap, however, is to put all of your logic and functionality directly into a TriggerHandler or TriggerHelper class. Individual functionality should be broken out into separate classes, called by the TriggerHandler. Not doing so leads us very quickly to unmaintainable code. This breaks the ‘Single-Responsibility Principle’ by causing it to do everything about an object’s trigger actions, and creating a ‘God object’, an anti-pattern.

For objects with a super simple trigger (e.g., only calling a single action), it can make sense to omit a handler class and directly call the trigger action from within the trigger. However, the actions should be written with a handler in mind, and should be migrated to one as soon as the trigger’s complexity increases.

12. Avoid Returning JSON to Lightning Components
When we’re writing @AuraEnable methods for our Lightning Components, we frequently need to return more complex data structures, such as records, custom data types, or lists of these types.
An easy approach would be to serialize these objects into JSON, and then deserialize them within our component’s JavaScript (that is what the JS in JSON standards for after all!).
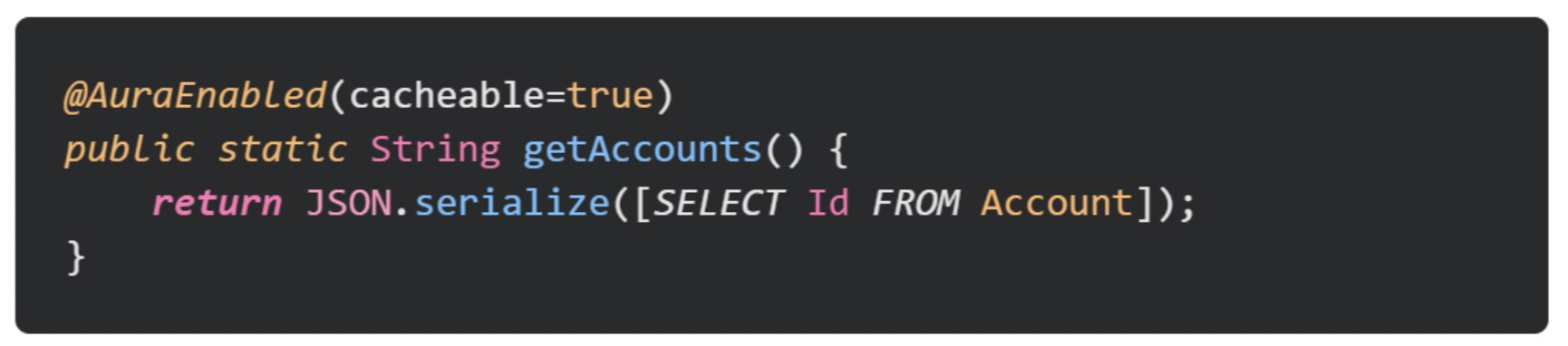
However, this approach is actually an anti-pattern and can lead to some poor performance within our components. Instead, we should be directly returning these objects and letting the platform handle the rest for us.
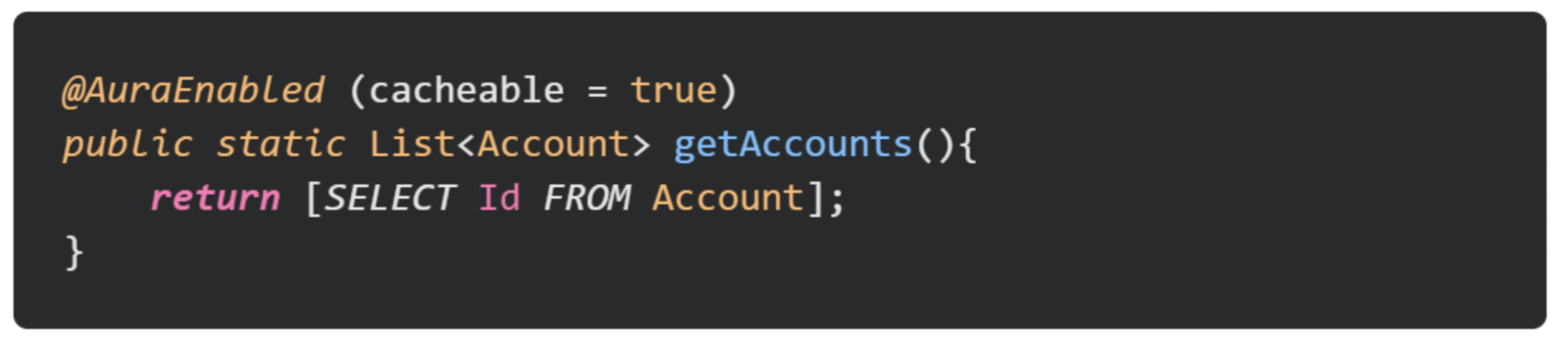
Converting our returned data into JSON results in us consuming large amounts of heap memory and spending many CPU cycles converting these objects into a lovely and long string. If there’s a rather complex set of processing going on, or perhaps if we have a large number of records to return, we can very quickly run into governor limits, or just poor performance in general, within our components.
When we directly return our result, the serialization into JSON (since it must be converted to JSON to be transmitted across the internet!) is handled by the platform, outside of our governor limits. The result is also automatically converted back into objects for our components to consume, without having to perform as many expensive JSON.parse() operations.
No comments:
Post a Comment